Having recently been exposed to the idea of open data and being relatively new in the research world, I personally believe that openness is a great concept. It encourages reproducibility, ensures data isn’t lost over time and exposes new areas of research and collaboration. However, I think the major barrier to openness becoming commonplace, especially in the field of ecology, is the amount you have to learn in order to become fully open and reproducible.
The massive learning curve ahead is certainly daunting. As a first year PhD student, I already feel like I have a heap to learn and adding more things to the list does not feel particularly encouraging. Norman Morrison (University of Manchester) presented a great slide illustrating this point at the recent workshop on “open data and reproducibility: the good scientist in the open science era” run by the BES Macroecology SIG and Methods in Ecology and Evolution:
The massive learning curve ahead is certainly daunting. As a first year PhD student, I already feel like I have a heap to learn and adding more things to the list does not feel particularly encouraging. Norman Morrison (University of Manchester) presented a great slide illustrating this point at the recent workshop on “open data and reproducibility: the good scientist in the open science era” run by the BES Macroecology SIG and Methods in Ecology and Evolution:
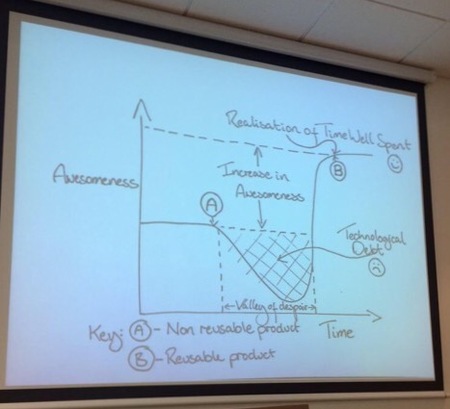
His amazing figure shows the journey someone like me has to go through to reach peak awesomeness in terms being fully open and reproducible with their work. Clearly the part I, and others like me, dread the most is the “valley of despair”. This massive drop in awesomeness is where we are stuck with a technological debt of knowledge in how to be reproducible. Although the end point of having a reusable product and the realisation of time well spent (point B/smiley face) seems like a great place to be, is it really worth all that time and effort?
Well, one portion of the meeting was dedicated to showing us just how easy it is to become more reproducible and the ease with which we can ensure our data is openly available. One great option is publishing data within data journals. These journals are providing a platform to make data available whilst being able to give credit to those who collected it. They are often linked with repositories so that you are also making the data easy to access for others who might wish to use it. The repositories themselves offer long-term storage and accessibility of data and there are many options available for different data types. Those commonly used for ecological data include GBIF, figshare, Dryad and the NERC data centres. A range of software options were also introduced including; ISA-Tab for storing metadata information alongside data, the R package knitr for producing clear and reproducible code and the Zoön software for performing reproducible species distribution models. I had a go at using knitr as part of the Reproducible Research online course available through Coursera. It is a really easy way to integrate text and R code to produce an annotated report-like piece whilst being able to produce outputs and plots as you go along. It makes reading through code a lot easier than navigating through a set of hashed comments!
I don’t know about anyone else but I will certainly be looking into some of the options presented at the workshop and will attempt to take that leap into the valley of despair! I do hope, however, that these tools and methods are incorporated into university programs in the future. If we want the field of ecology to be open and reproducible we need to get people working in this way from the very start of their career. I know I am certainly wishing I had started to learn all of this during my undergrad! Let’s hope this starts soon so that others do not have to go through such a dramatic drop in awesomeness to reach that smiley face at the end.
 RSS Feed
RSS Feed
